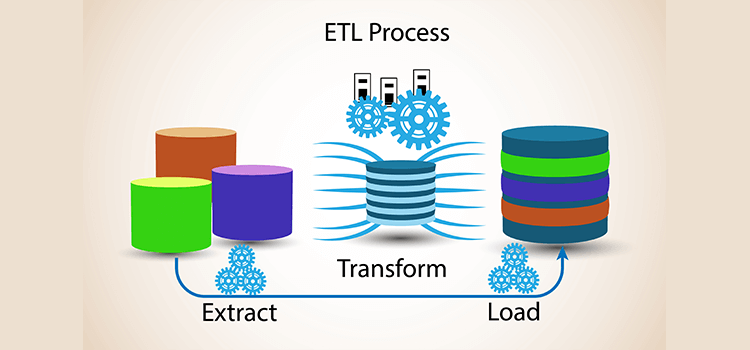
ETL simply stands for Extract, Transform & Load. In computing, extract, transform, load is the general procedure of copying data from one or more sources into a destination system which represents the data differently from the source or in a different context than the source. Wikipedia

ETL is an automated process, referring to three separate functions combined into a single tool, that includes taking raw data, extracting the information required for analysis, transforming into a format that serve the business needs, and then loading it to the data warehouse. It typically reduces the size of the data and improve the performance for analysis purpose and managing the databases.
To ensure the correct transformation of source data, one must integrate the data sources and carefully plan and test while building an ETL infrastructure.
Extract
Extract is the first step of an ETL process, which involves extracting of the data from a source system. It is the most important segment of an ETL process as the success of all other upcoming steps depend on how correctly the data has been extracted. Data is validated as per set validation rules which may vary in each case. The data is collected often from multiple and different types of sources.
There are three methods for Data Extraction:
• Full Extraction;
• Partial Extraction (without update notification);
• Partial Extraction (with update notification).
Transform
Next step is Data Transformation. In this stage, a series of rules or functions gets applied to the extracted data so it can be prepared into a desired format to get loaded into the end target. Data cleansing is important part of Data Transformation.
Load
The Load stage, as obvious from its name, loads the data into the end target. It is used to write the data into the target database. There are three types of Loading:
• Initial Load (Populates all the data warehouse tables);
• Incremental Load (Applies ongoing changes as when needed);
• Full Refresh (Erases the contents of one or more tables and replaces with new data).
ETL Importance
It is an IT process which puts data from incongruent sources into one place and an important part of today’s business intelligence processes and systems to programmatically analyze and discover business insights. Businesses have been relying on the ETL process to get consolidated view of the data from many years to make better business decisions and it is still a core component of an organization’s data integration system.
• ETL makes it quite easy for a business to analyze the data and create reports that can help in making decisions for their initiatives, through the consolidated view;
• ETL provides detailed historical perspective for the business when used with an enterprise data warehouse;
• ETL codifies and reuses the processes without requiring technical skills to write code or scripts which can improve data professional’s productivity;
• ETL has evolved over time to support emerging integration requirements like for streaming data.
Traditional ETL
For many years traditional ETL was the only way to extract and transform the data from the operational systems and load to the data warehouse for analysis purpose. In this, the data is extracted from the transactional databases and other data sources with read and write requests and then transformed into a staging area which covers data cleansing and optimization of the data for the analysis. This transformed data is then loaded into an online analytics database which is used by Business Intelligence teams to run queries and presented for making business decisions. The tools used are designed to integrate the data in batches.
Historically, the process has looked like:

Modern ETL
With the change in modern technology, most organizations’ approach to ETL has changed too. The contributing factors include the arrival of powerful analytics warehouse like Amazon Redshift and Google BigQuery. These databases have the power to perform transformations in place rather than requiring a special staging area. Modern tools are built keeping microservices in mind that enable the process to store, stream, and deliver data in real-time. The speedy shift to cloud-based SaaS applications is another factor as these applications have significant amount of business-critical data in their own databases which are accessible through different technologies such as APIs and webhooks. This has resulted in lightweight, flexible, and transparent ETL processes that look like:

ETL process comes with its own challenges and flaws that can potentially contribute to various set of losses in any ETL project. Data loss during ETL Testing, Data Incompatibility and Absence of business course information can lead to serious complexities for any team performing ETL process.
Complexities Of An ETL Project
An ETL opportunity or a project looks exciting, but it comes with its own challenges and complexities.
Initial set of data and its volume can change over time. The data volume can increase and hence its analysis gets complicated. Maintenance costs go up and all other relative attributes to data format changing can add additional effort and time.
Data from different sources does not go along smoothly and in some cases need a lot of effort to work together. These efforts can be time consuming.
Building Architecture for an ETL project can be tricky. Going straight to coding without taking into consideration the overall bigger picture can cause serious problems for your team performing an ETL job.
If there is a need for real time updates, there are several tools available for this. For an ETL project to be a success first thing is to get the fundamentals right in place. Tools are secondary.
There are certain issues that can be related with any data, which effects the ETL process. The process needs to be able to handle a variety of data formats when pulled in from different sources. The process needs to be fault tolerant and has the ability of recover gracefully, as problems can occur inevitably, making sure the data can transfer from one end of the pipeline to the other end when it encounter issues.
The quality of data, types of independencies that exist in the data, how complex are the data relationships etc. This all can influence the ETL process. There can be difficulty in accessing data from different systems and quality of the data is not ensured. The data might be inconsistent too.
Compatibility of the source and target data and scalability of the ETL process are common technical challenges. Scalability can be a tricky issue that you may come across and it depends on the size of the data you are dealing with. There can be operational changes in source data systems, and ongoing revisions to target schema definitions and scope. This all adds complexity to ETL process. Ensuring Data Quality in any ETL process is challenging due to all these dependencies. Duplicate record is another challenge. Conflicting and duplicate records are common data problems that can significantly affect the efficiency of an ETL process and output data quality.
Integrating data across different sources is challenging. It entails programming of Scripts to parse the source data. If standard drivers are not available there will be coding needs to be taken care of to complete the desired function. All this adds complexity to an ETL process.
Data Consistency is a challenge at Transformation state as data collected from different sources can have uncertainty.
At the time of Loading or populating the data the challenge is the time needed to populate a Data Warehouse.

Best Practices To Overcome ETL challenges
Understanding the overall project and expectations and detailed analysis of the requirements will help design a robust and flexible ETL architecture accordingly. When the data tables are large then loading data incrementally is the solution as it makes sure that the last updates are brought into the ETL process. Updates should not get missed as else there will be redoing of tasks. Loading incrementally improves the overall efficiency of an ETL process. To overcome the challenges, it is best advised to focus on the bottlenecks, load data incrementally, break down large tables into small ones and use parallel processing.
Conclusion
In any ETL process or a project you are prone to come across many challenges. However, with the right approach these challenges can be met. Soft Tech Group strongly recommends Dynamic ETL solution. It supports the flexibility and makes its easier to perform a successful ETL process. It minimizes the overall challenges being faced during an ETL project.
Let's build something amazing together. Contact us to get started.